
Unpriced climate risk and the potential consequences of overvaluation in US housing markets
Property transaction data
We combine the Zillow ZTRAX database49 and the PLACES database50 to access property transactions, locations, and assessments for all states in the conterminous United States between 1996 and 2021. The ZTRAX database, provided to us by Zillow, contains property transaction and tax assessment data for approximately 150 million parcels in over 3,100 counties nationwide (Supplementary Fig. 1). To ensure consistency and accuracy of the data across the United States, we extensively processed the ZTRAX database based on the recommendations in ref. 26. These data cleaning measures included identification of arms-length sales, geolocation of parcels and buildings, temporal linkages between transaction, assessor and parcel data, and the identification of property-types, such as single-family homes. More information on accessing the Zillow ZTRAX database can be found at www.zillow.com/ztrax.
The PLACES database uses assessor parcel numbers to link ZTRAX data to parcel boundaries using county- and town-specific string pattern matching and geographic quality controls. For approximately one third of United States counties, parcel polygon data in PLACES comes from open-access sources; for the remainder, parcel polygon data comes from Regrid through their ‘Data with Purpose’ program (https://regrid.com/purpose). The matching algorithm identifies over 1,000 unique combinations of syntaxes and links digital parcel boundaries from 2,951 counties to ZTRAX data with a median county-level success rate of 98.2% and a mean of 95.5% (measured as the percentage of the number of parcel boundaries matched to a tax assessor record). These linkages were used to identify the parcels and transactions in our statistical models.
Flood hazard data
We evaluated properties’ exposure to fluvial, pluvial and coastal flood hazards in the years 2020 and 2050 using previously developed inundation maps29. These maps provide estimates of inundation depths at a 30 m spatial resolution under 5, 20, 100, 250 and 500 yr flood recurrence intervals in both years. The 2020 model outputs were validated by simulating historical flood events and comparing them to observed flood extents and depths, finding 87% similarity between the two51. Further validation of model outputs is described in the First Street Foundation technical documentation52. The 2050 estimates are based on downscaled Coupled Model Intercomparison Project 5 data under RCP 4.5. These data have been made available by the First Street Foundation and can be found on their website (www.floodfactor.com).
While uncertainty and disagreement remain across continental-scale flood models in terms of which areas are most exposed and the extent of future flooding53, the outputs from ref. 29 provide the only peer-reviewed, publicly available, climate-adjusted, and historically validated US-scale flood model that has a high enough resolution to be property specific. Other high-resolution models do exist in the private sector, but are generally not made available for research purposes or are made available without transparent methods.
Calculating flood losses
We calculated expected annual flood losses to single-family homes in the United States using the methods described in ref. 54. In brief, we overlaid the locations of residential structures derived from the ZTRAX and PLACES databases with the flood inundation maps and applied depth-damage functions recommended by FEMA55. These functions were developed through expert elicitation and are used to estimate the damage to inundated properties as a proportion of their value based on flood depth relative to first-floor elevation.
While depth-damage functions are widely used in flood risk assessments nationally, including FEMA’s HAZUS-MH software, these functional relationships are highly uncertain and depend on numerous property-specific characteristics56. Unfortunately, many of these characteristics are not included in the ZTRAX data, such as first-floor elevations and structure types. To address the issue of missing first-floor elevations, which are crucial for translating inundation depths to depths relative to the first floor, we applied adjustments to inundation depths based on the recommendations in Sections 5.6.1–5.6.3 of the HAZUS Technical Methodology manual57. To overcome the limitation of incomplete structure records, we used the proportions of structure types found in the NFIP policies data, as described in ref. 54.
To calculate AALs for each property in 2020 and 2050, we integrated the estimated damages over the range of recurrence interval probabilities modelled in ref. 29 using trapezoidal Riemann sums58. In a given year, the probability p of one of these events occurring is 1/T, where T equals the expected recurrence interval (for example, p = 0.05 for a 20 yr flood event). These probabilities are independent of each other, such that multiple flood events can occur in a single year. To estimate AALs for property i in year t between 2020 and 2050, we used a simple linear interpolation, where t = 0 is the year 2020 (equation 1).
$$\mathrm{AAL}_{it} = \mathrm{AAL}_{i2020} + t \times \frac{{\left( {\mathrm{AAL}_{i2050} – \mathrm{AAL}_{i2020}} \right)}}{{30}}$$
(1)
We calculated the NPV of AALs for property i over a 30 yr time horizon (that is, the duration of a typical fixed-rate mortgage), where ρ is the discount rate (equation 2). All results are reported using a 3% discount rate, unless stated otherwise. The NPVs of AALs by county are shown in Supplementary Fig. 3.
$$\mathrm{NPV}_i = \mathop {\sum }\limits_{t = 0}^{30} \mathrm{AAL}_{it}(1 + \rho )^{ – t}$$
(2)
Historical flood insurance rate maps
We employed data from all FIRMs released across the United States between 2005 and 2019 to determine each property’s FEMA-designated flood zone at the time of sale. We obtained these data through Freedom of Information Act requests and one-on-one meetings with former GIS analysts who performed contractual work for FEMA. Specifically, we used a digital version of the paper-based flood maps that were effective before 2005 (called the Q3 data product), combined with yearly snapshots of the National Flood Hazard Layer between 2012 and 2020. For each FIRM, we observed the date when the map became active (Supplementary Fig. 4), as well as the spatial extent of the 100 yr and 500 yr floodplains. Comparing the evolution of the spatial polygons through time allowed us to identify changes in floodplain boundaries at the property level. Currently, more than 115 million or 90% of residential properties are covered by the digital FIRMs. Details on the data collection and cleaning steps are provided in ref. 27.
Estimating flood risk capitalization
The extent to which exposure to flood risk is capitalized in property values is driven by many dynamic factors, including recent local experience with flooding, insurance mandates, the cost of insurance (not just in the NFIP, but also private sector options), awareness of non-insurable costs, perceptions of risk and available information, not just from mandated disclosures, but also from others involved in the market, such as realtors or neighbours. In this analysis, we necessarily averaged away some of this heterogeneity and examined capitalization of flood risk among properties located within the SFHA. Specifically, we used capitalization of updated information about flood risk as an imperfect proxy for capitalization of exposure to flood risk (relative to not being exposed to any risk).
We estimated the empirical flood zone discount (that is, observed capitalization) using a panel model for repeat property sales. This method has been applied by several other recent studies to estimate the effects of flood events and flood zone remapping on property prices59,60,61,62,63, and is considered best practice in this context25. Similar to the approach used in ref. 9, we identified the effect of flood zone status on property prices by comparing single properties to themselves over time, as they are rezoned from outside to within the SFHA due to FIRM updates. A key advantage of this identification approach, particularly compared with cross-sectional models, is that it is less vulnerable to the confounding effects of time-invariant property-specific attributes, such as waterfront amenities, which are often spatially correlated with flood risk9,10.
As shown in equation (3), we estimated the effect of location within the SFHA (δ) on the sale price (p), where SFHAit is a binary variable equal to 1 if property i is located in the SFHA at time t. Property-level fixed effects, γi, control for all time-invariant characteristics of a property. We also included county-by-year fixed effects, \(\eta _{ct}\), to control for local market dynamics over time. These fixed effects absorb shocks to the housing market caused by natural hazards, including past flood events. α is a constant and εit is an error term. For a property to be included in the estimation sample, it must: (1) be outside of the SFHA in the old FIRM, (2) have a known floodplain status in the new FIRM and (3) be sold more than once while its flood zone status is known. Sales that occurred while the flood zone status was unknown were omitted from the dataset.
$$\mathrm{log}\left( {p_{it}} \right) = \alpha + \delta _g\mathrm{SFHA}_{it} + \gamma _i + \eta _{ct} + \varepsilon _{it}$$
(3)
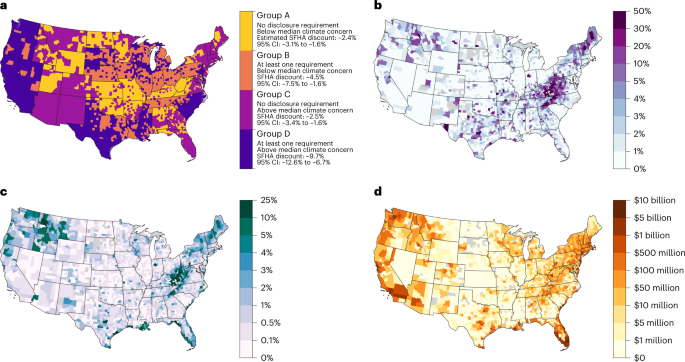
We accounted for variation in the empirical flood zone discount, indicated by the subscript g, driven by differences among state-level flood risk disclosure laws and individual perceptions of climate risk by creating four groups of counties. Across the United States, states vary widely in what they require sellers to disclose to buyers. Based on data compiled by the Natural Resource Defense Council, we grouped states by their disclosure laws or lack thereof. Using the Yale Climate Survey, we also grouped counties based on average responses to the question “Do you think global warming will harm you personally?” (Supplementary Fig. 5). Group A comprises counties with no disclosure laws and below median climate concern; Group B comprises counties with at least one form of disclosure law and below median climate concern; Group C comprises counties with no disclosure laws and above median climate concern; Group D comprises counties with at least one form of disclosure law and above median climate concern. Due to the relatively small sample size of properties remapped into the 100 yr flood zone, we were unable to group counties with more granularity.
This approach makes two key assumptions about the dynamics of flood risk capitalization among rezoned properties and properties located outside the SFHA. First, we assume that properties rezoned into the SFHA are representative of all properties located in the SFHA. While rezoned properties may be on the margins of the SFHA and have lower flood risk than average SFHA properties, rezoned properties may also be less adapted to flood risk than average SFHA properties, since the latter have been subject to floodplain building codes for years. Respectively, these two potential differences may simultaneously lead to under- and overestimation of flood risk capitalization.
Second, we assume that only properties currently located within the SFHA capitalize flood risk, whereas properties located outside the SFHA do not experience any discount despite their exposure to flood risk. We make this assumption based on the results of refs. 9,10,24, all of which find that location in the FEMA-designated 500 yr floodplain (that is, 0.2–1% annual probability of flooding) has no effect on property sale prices. We describe two alternative analyses that test the sensitivity of this assumption at the end of the Methods section.
Estimating property overvaluation
We calculated overvaluation of properties exposed to flood risk (that is, both SFHA and non-SFHA properties with flood losses greater than zero) as the difference between their estimated current fair market value and their efficient price (equation 4). For properties where the fair market value is less than the efficient price, we calculated overvaluation as zero.
$$\mathrm{Overvaluation}_i = \mathrm{FairMarketValue}_i – \mathrm{EfficientPrice}_i$$
(4)
We estimated the current fair market value of properties using their most recent transaction price adjusted to the present using the Federal Housing Finance Agency’s House Price Index (FHFA HPI). For properties with no transaction data, we instead used their assessed value, similarly adjusted to the present using the FHFA HPI, depending on the year of assessment. We accounted for differences in assessment methods across counties by fitting simple linear regression models between adjusted transaction prices and adjusted assessed values for all transacted properties in a county. We then applied the estimated coefficient as a scalar to the assessed values.
We estimated the efficient prices of properties exposed to flood risk as the difference between their fair market value in the absence of any flood risk (RiskFreeMV) and the NPV of AALs between 2020 and 2050 (equation 5). For properties where the NPV of AALs is greater than the RiskFreeMV, the efficient price is zero.
$$\mathrm{EfficientPrice}_i = \mathrm{RiskFreeMV}_i – \mathrm{NPV}_i$$
(5)
The use of AALs to determine efficient prices assumes that homebuyers have complete information about properties’ exposure to flooding and price that risk according to the discounted value of future flood losses. Despite uncertainty in projections of future flood losses, this approach captures the potential cost of exposure to flood risk over the lifetime of a property more accurately than the current cost of NFIP premiums. In contrast to our estimates of AALs, NFIP premiums do not reflect future climate change, have been historically subsidized in many locations and have been based on FEMA flood maps, which are inaccurate and lack coverage in many parts of the United States. While some of these deficiencies in NFIP pricing have been addressed by Risk Rating 2.0, those data are not yet available at the property level. Further, given that housing markets have the potential to capitalize the total costs of flood risk under climate change, our estimates capture market overvaluation better than the costs of current NFIP premiums.
To calculate properties’ RiskFreeMV, we removed the empirical flood zone discounts (δ) estimated with the hedonic model (equation 6). For example, if the fair market value for property i is US$500,000 and the flood zone discount for group g is −5%, then the RiskFreeMV for property i is US$526,315. As discussed in the previous section, we assume that properties outside the SFHA do not capitalize flood risk and that their RiskFreeMV is the same as their current fair market value.
$$\mathrm{RiskFreeMV}_i = \left\{ {\begin{array}{*{20}{l}} {\mathrm{FairMarketValue}_i/(1 + \delta _g),\quad \mathrm{SFHA} = 1} \hfill \\ {\mathrm{FairMarketValue}_i,\quad \mathrm{SFHA} = 0} \hfill \end{array}} \right.$$
(6)
Importantly, the use of AALs to estimate efficient property prices inevitably results in the underestimation of overvaluation. Beyond structural damages, flooding is also associated with damages to contents and loss of sentimental items, debris clean up, evacuation expenses, and negative mental health impacts, none of which are included in the NPV of AAL estimates. While difficult to quantify, including these other forms of damage in the NPV calculation would invariably increase estimates of overvaluation.
Sensitivity and uncertainty analyses
In our main methods and results, we assume that properties located outside of the SFHA do not capitalize flood risk. However, particularly following recent flood events, exposure to flood risk may be temporarily capitalized by properties outside of the SFHA in localized areas64. To test the sensitivity of our results to this initial assumption, we reran the analysis with two alternative assumptions regarding flood risk capitalization and subsequent overvaluation.
In our first sensitivity analysis, we assume that all properties exposed to flood risk are discounted at the same rate as was estimated for SFHA properties by the panel model described above. This provides an upper-bound estimate of non-SFHA capitalization and a lower-bound estimate of total overvaluation. Results under this alternative assumption are shown in Supplementary Figs. 11 and 14.
In our second sensitivity analysis, we implemented a cross-sectional regression model to identify flood risk capitalization among properties exposed to flood risk and that are located in the FEMA 100 yr flood zone, 500 yr flood zone or outside of any designated flood zone. While this approach allowed us to estimate flood risk capitalization among properties located outside of the SFHA, we prefer it less than the panel model because of how challenging it is to control for all the characteristics of a property that may be correlated with flood risk and prices. The results from this analysis are shown in Supplementary Figs. 8, 12 and 15.
For this alternative analysis, we estimated the effect of FEMA flood zone status (δ) on sale price (p) using a 6-level factor variable (\(\mathrm{FZ}_{it} \ast \mathrm{Risk}_i\)) that combines flood zone categories (that is, 100 yr, 500 yr or outside) and binary exposure to flood risk (equation 7). Properties located outside of any flood zone and that are not exposed to flood risk serve as the reference group. Hit is a vector of property-specific variables that includes number of bedrooms, building area and the age of the property at the time of sale; λ is a vector of estimated coefficients for these variables. Following ref. 40, we applied high-dimensional fixed effects, β, to control for a suite of location-specific characteristics (Xi). This term captures the interaction between a property’s block group, distance to coast bins (0 to 10 m, 10 to 400 m, >400 m), presence of lake and river frontage on the property and elevation bins (0 to 5 m, 5 to 10 m, >100 m). We also applied fixed effects to control for seasonal market trends across states, \(\tau _{sq}\), and county-level market trends across years, \(\eta _{ct}\). We performed this estimation for sales within each subset of Groups A–D defined above. To calculate overvaluation, we changed any estimate of δ that is greater than zero (that is, a price premium) or not significantly different (P ≥ 0.05) to zero.
$$\mathrm{log}\left( {p_{it}} \right) = \alpha + \delta _g\mathrm{FZ}_{it} \ast \mathrm{Risk}_i + {\uplambda}H_{it} + X_i + \tau _{sq} + \eta _{ct} + \varepsilon_{it}$$
(7)
Separate from these two sensitivity analyses, we also used a Monte Carlo simulation to evaluate the uncertainty bounds in our estimates of overvaluation. For each iteration of the simulation (N = 1,000), we randomly sampled normal probability distribution functions fitted to the empirical flood zone discounts estimated by the panel model (see equation 3). We also assessed the sensitivity of overvaluation to the applied discount rate, comparing discount rates of 1, 3, 5 and 7%, and inundation hazard scenarios. The low, mid and high hazard scenarios represent the 25th, 50th and 75th percentile estimates of the flood model simulations, respectively. Variation across flood model simulations is driven by uncertainty in global climate model outputs. In 2050, the 25th and 75th percentile estimates from the RCP 4.5 model roughly align with the mean estimates from the RCP 2.6 and 8.5 models. For more information on the uncertainty in flood model outputs, please see ref. 29. Results from the uncertainty analysis are shown in Supplementary Fig. 16.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}